Table of Contents
H Beam Vs I Beam
Steel is the most adaptable, regularly used structural material. Both H Beam and I beam are the most common structural elements used in commercial building construction.
Both are similar in shape for regular people, but there are significant differences between these two, which are essential to know.
The horizontal part of both H and I beam is termed as flanges, while the vertical part is known as the “web.” The web helps to bear shear forces, while the flanges are designed to withstand the bending moment.
What is I Beam?
It is a structural component that a shape like a capital I. It consists of two flanges connected by the web. The inner surface of both the flanges has slop, usually, 1:6, which makes them thick inside and thin outside.

As a result, it performs well at bearing load under direct pressure. This beam has tapered edges and higher cross-section height as compared to the width of the flange.
Based on the use, I-beam sections are available in a range of depth, web thickness, flange widths, weights, sections.
What is H Beam?
It is also a structural member that shapes like a capital H consist of rolled steel. H section beams are widely used for commercial and residential buildings due to their strength to weight ratio and superior mechanical properties.

Unlike the I beam, the H beam flanges don’t have an inside inclination, making the welding process easy. Both flanges have equal thickness and are parallel to each other.
Its cross-sectional characteristics are better than I beam, and it has better mechanical properties per unit weight that save material and cost.
It is the favoured material for platforms, mezzanines, and bridges.
Difference Between H Beam and I Beam
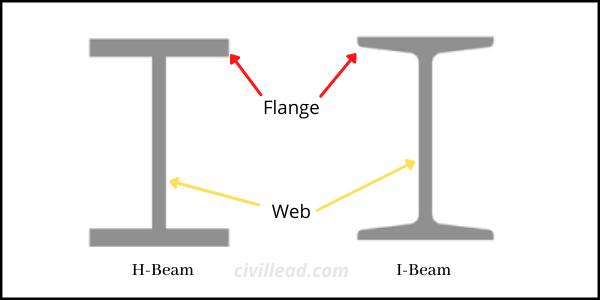
At first look, both H-section and I-section steel beams look similar, but there are some critical differences between these two steel beams that are essential to know.
Shape
H beam resembles the shape like Capital H, while I beam the shape like capital I.
Manufacturing
I-beams are manufactured as a single piece throughout, while H-beam comprises three metal plates welded together.
H-beams can be fabricated to any desired size, while the milling machine capacity limits the production of I-beams.
Flanges
H beam flanges have equal thickness and are parallel to each other, while I beam have tapered flanges with an inclination of 1: to 1:10 for better load-bearing capacity.
Web Thickness
H beam has a significantly thicker web as compared to the I beam.
Number of pieces
H-section beam resembles a single metal piece, but it has a bevel where three metal plates are welded together.
Whereas an I-section beam is not produced by welding or riveting metal sheets together, it is only one section of metal entirely.
Weight
H beams are heavier in weight as compared to I beam.
Distance From Flange end To Web’s centre
In I-section, the distance from the flange end to the Web’s centre is less, while in H-section, The distance from the flange end to the Web’s centre is higher for the similar section of the I-beam.
Strength
H-section beam gives more strength per unit weight due to more optimized cross-sectional area and an excellent strength to weight ratio.
Generally, I-section beams are deeper than wide, making them exceptionally good at bearing load under local buckling. Furthermore, they are lighter in weight than H-section beams, so they will not take a significant load as H-beams.
Rigidity
In general, H- Section beams are more rigid and can take a heavier load than I-section beams.
Cross-section
The I-section beam has a narrow cross-section suitable for bearing direct load and tensile stresses but is poor against twisting.
In comparison, the H beam has a broader cross-section than the I beam, which can handle the direct load and tensile stresses and resist twisting.
Ease of Welding
H-section beams are more accessible to weld due to their straight outer flanges than I-section beams. H-section beam cross-section is more robust than I-section beam cross-section; hence it can take a more significant load.
Moment of Inertia
The Moment of Inertia for a beam determines its capacity to resist bending. The higher it will be, the less the beam will bend.
H section beams have wider flanges, high lateral stiffness, and greater moment of inertia than I-section beams, and they are more resistant to bending than I beam.
Spans
An I-section beam can be used for a span up to 33 to 100 feet due to manufacturing limitations, while an H-section beam can be used for a span up to 330 feet since it can be made in any size or height.
Economy
An H-section beam is a more economical section with enhancing mechanical properties than an I-section beam.
Application
H-section beams are ideal for mezzanines, bridges, platforms and the construction of typical residential and commercial buildings. They are also used for the load-bearing column, trailer and truck bed framing.
I-section beams are the adopted section for bridges, structural steel buildings and the making of support frames and columns for elevators, hoists and lifts, trolley ways, trailer and truck beds.
Final Words
I believe now you have a clear understanding of the difference between the H beam and the I beam. Both steel beams are widely used in the construction business. The best one is entirely subjective and depends on their application.
If you find this information knowledgeable, please share it. If I have missed any differences between these two steel beams, let me know in the comment section.
Thanks!
Also, Read
Difference Between Tension and Compression
Beam vs Column – 12 difference Between Beam and Column
Grade Beam – Grade Beam Foundation, Construction Process, Advantages & Disadvantage
How to Calculate Unit Weight of Steel bars?
Difference Between English Bond and Flemish Bond
8 Types of Stairs, Flight of Stairs